library(rio)
peru_data = import("./data/s7/Peru_Latinobarometro2020.sav")8 Pregunta 1 (3 puntos)
- Importar la base de datos
Se requiere analizar la cultura política del Perú sobre la confianza.
• ¿Cuál es la institución (P13STGBS) en la que más confían (mucha confianza) los peruanos y peruanas? Calcule su intervalo de confianza al 95% de nivel de confianza.
9 Ir al cuestionario (o diccionario) –> encontramos 9 instituciones y son variables Ordinales: están codificados como (mucha, algo, poca, ninguna)
#Darle Formato a las variables
- Renombrando:
colnames(peru_data) [41] <- "FuerzasArmadas"
colnames(peru_data) [42] <- "LaPolicia"
colnames(peru_data) [43] <- "LaIglesia"
colnames(peru_data) [44] <- "Congreso"
colnames(peru_data) [45] <- "Gobierno"
colnames(peru_data) [46] <- "PoderJudicial"
colnames(peru_data) [47] <- "PartidosPoliticos"
colnames(peru_data) [48] <- "JNE"
colnames(peru_data) [49] <- "ElPresidente"#Entonces, calcularemos una tabla por cada una de las variables ordinales
table(peru_data$FuerzasArmadas)
1 2 3 4
201 361 420 200 table(peru_data$LaPolicia)
1 2 3 4
91 278 499 317 table(peru_data$LaIglesia)
1 2 3 4
420 339 286 141 table(peru_data$Congreso)
1 2 3 4
18 70 329 765 table(peru_data$PoderJudicial)
1 2 3 4
35 161 394 581 table(peru_data$PartidosPoliticos)
1 2 3 4
14 72 311 783 table(peru_data$JNE)
1 2 3 4
68 312 467 330 table(peru_data$ElPresidente)
1 2 3 4
96 273 373 417 #identicados los casos, Al observar las tablas determinamos esto:
Comando describe para ver a las 9 varaibles:
#install
# library(Hmisc)
# describe(peru_data)[41:49]- calculamos lo que nos pide la pregunta 1: (todo es respecto a los datoa de iglesia en el describe)
prop.test(x=c(420), n = c(1186), conf.level = 0.95)
1-sample proportions test with continuity correction
data: c(420) out of c(1186), null probability 0.5
X-squared = 100.36, df = 1, p-value < 2.2e-16
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.3270112 0.3822083
sample estimates:
p
0.3541315 9.1 INTERPRETACIÓN:
- La iglesia es la institución en la que más confían los peruanos y peruanas. El 35% confía mucho en esta institución. A un 95% de nivel de confianza, el porcentaje oscila entre el 32.7% y el 38.2%.
9.1.1 Pregunta 2 (3 puntos)
#• ¿Cuál es la institución en la que menos confían (confían nada) los peruanos y peruanas? Calcule si existe una diferencia de proporciones entre quienes no confían nada según su sexo. Al 95% de nivel de confianza . ¿Qué se puede concluir acerca de las diferencias entre hombres y mujeres?
#Observamos las tablas que hemos hecho. Advertimos que son los partidos políticos en los que menos confían.
#Pide un prop.test #pero antes, defino como factor (es una variable nominal) y darle su formato a las variables (sexo) #luego calculamos su tabla
- Formato:
peru_data$SEXO = as.factor(peru_data$SEXO)
peru_data$SEXO = factor(peru_data$SEXO,
levels = levels(peru_data$SEXO),
labels = c("Hombre","Mujer"),
ordered = F)
table(peru_data$SEXO)
Hombre Mujer
600 600 sum(is.na(peru_data$SEXO)) # No hay NA's[1] 0sum(is.na(peru_data$PartidosPoliticos)) # Sí hay 20 NA's[1] 20peru_data = peru_data[complete.cases(peru_data$PartidosPoliticos), ] # Borramos NA´stable(peru_data$PartidosPoliticos, peru_data$SEXO) # Tabla de contigencia cruzada:
Hombre Mujer
1 9 5
2 43 29
3 176 135
4 362 421addmargins(table(peru_data$PartidosPoliticos, peru_data$SEXO)) # Para observar las tablas marginales y condicionadas
Hombre Mujer Sum
1 9 5 14
2 43 29 72
3 176 135 311
4 362 421 783
Sum 590 590 1180- Tabla de proporciones: calculando LAS PROPORICONES CON RESPECTO A LAS COLUMNAS. Las Columnas suman 1, en este caso 100 % (*100):
prop.table(table(peru_data$PartidosPoliticos,peru_data$SEXO),2)*100
Hombre Mujer
1 1.5254237 0.8474576
2 7.2881356 4.9152542
3 29.8305085 22.8813559
4 61.3559322 71.3559322- ahora procedemos con prop.test (lo que nos pide la pregunta): (en este caso, coinciden la cantidad de hombres y mujeres):
prop.test(x = c(421,362), n = c(590,590), conf.level = 0.95) #Diferencia de confían nada entre mujeres y hombres
2-sample test for equality of proportions with continuity correction
data: c(421, 362) out of c(590, 590)
X-squared = 12.77, df = 1, p-value = 0.0003523
alternative hypothesis: two.sided
95 percent confidence interval:
0.04469015 0.15530985
sample estimates:
prop 1 prop 2
0.7135593 0.6135593 HIPOTESIS NULA: No hay diferencia de proporciones entre quienes no confían nada en los partidos políticos de acuerdo al sexo de las personas / Las proporciones son iguales.
p-value = 0.0003523. De acuerdo con el criterio del 0.05. Podemos señalar que el p-value es menor, por tanto rechazamos la H0. Es decir, hay diferencia estadisticamente significativa.
9.2 INTERPRETACIÓN:
La institución en la que menos confían los peruanos y las peruanas son los partidos políticos.
A un nivel de confianza del 95%, el porcentaje de mujeres que confían menos (
nada) en partidos politicos es significativamente diferente que el porcentaje de sus pares que tienen la misma percepción.En efecto, se observó que el porcentaje de mujeres (
71 %) es mayor que el porcentajes de hombres (61 %) que comparten la misma sensión sobre los partidos politicos.Además, la diferencia de porcentajes oscila entre el 4% y el 15%.
Por tanto, se concluye que sí existe diferencia significativa entre quienes no confían nada en los partidos políticos de acuerdo al sexo de las personas.
NOTA: Cuando el intervalo de confianza de la diferencia de dos medias o dos proporciones incluye al cero , no hay diferencias significativas.#
9.3 GRAFICA
library(ggplot2)
p <- ggplot(data = peru_data,
mapping = aes(x = factor(PartidosPoliticos),
fill = factor(SEXO)))
p + geom_bar(position = 'fill', stat = 'count')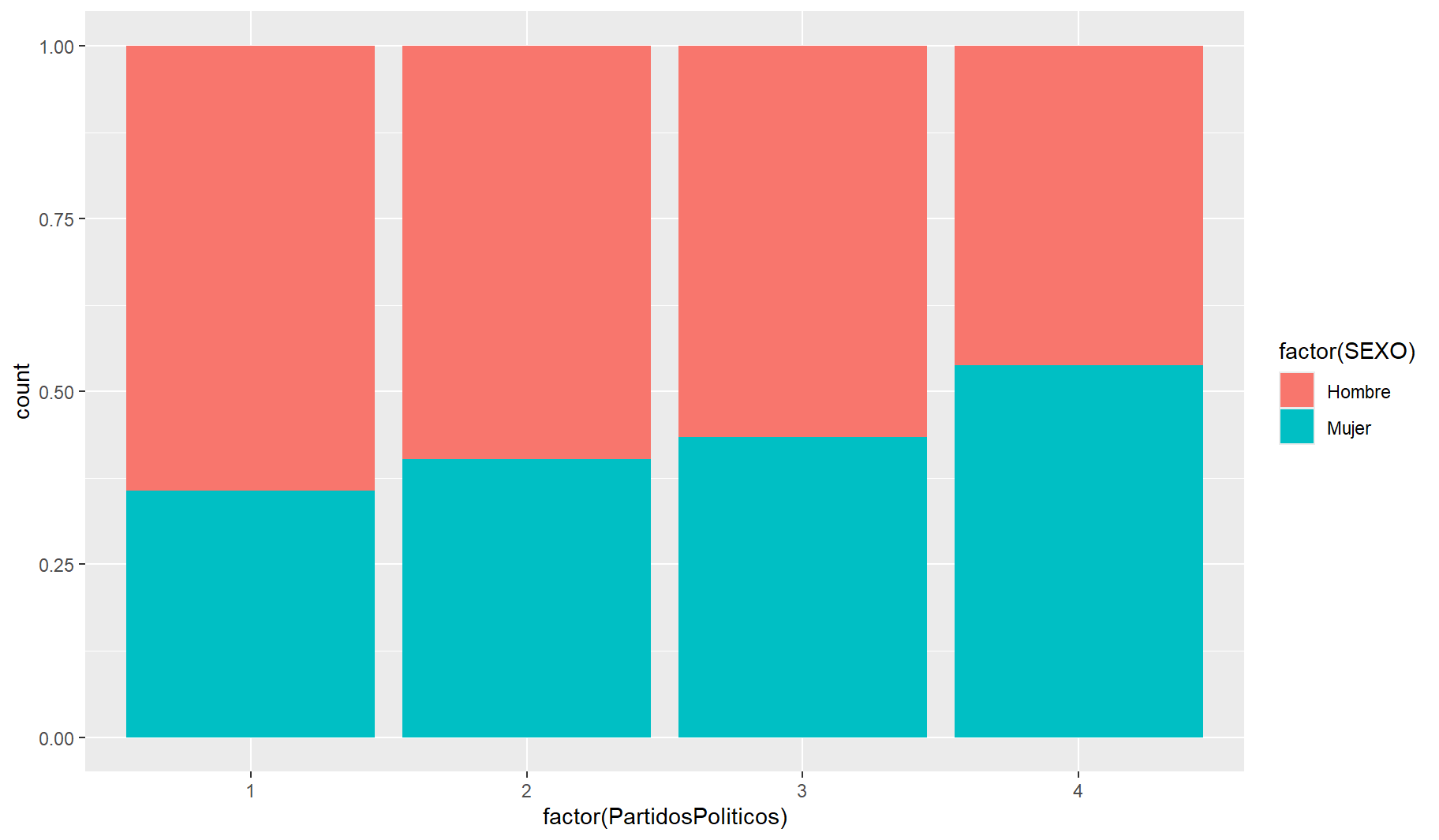
10 Pregunta 3 (3 puntos)
• Construya un indicador (0 a 100) sobre la CONFIANZA INSTITUCIONAL DE ORGANIZACIONES DE LA SOCIEDAD CIVIL (ONGs, Sindicatos, Medios de Comunicación y Organismos multilaterales) . Informe sobre el comportamiento de dicha variable (P15ST). Calcule el intervalo de confianza al 95% de nivel de confianza.
#Entonces, vamos al cuestionario/diccionario de datos #Indicador (Mínimo (Falta de confianza)) - (Máximo (Mayor de confianza)). #Por ejemplo: #Indicador (Pobreza) #Menor puntaje – Menos Pobreza #Mayor puntaje – Mayor Pobreza
#El problema es que El sentido está al reves, e enefecto, si se suma 1 (mucha) 4 veces obtienes 4, pero con 4 (nada) se obtedría 16. ##Siendo 1 (Mucha), 2 (Algo),3 (Poco) y 4 (Nada). 8 No sabe 0 No responde
- ONG: P15ST.A
- Sindicatos: P15ST.C
- Medios de comunicación:P15ST.D
- Organismos multilaterales: P15ST.G #Entonces, TENEMOS QUE RECODIFICAR:
#Recodificación
- 1 Mucho — 4
- 2 Algo —- 3 3 Poco —2 4 Ninguno —1
Cambiar el sentido de las 4 variables:
table(peru_data$P15ST.A)
1 2 3 4
107 353 417 234 library(car)
peru_data$ONG=recode(peru_data$P15ST.A,"1=4; 2=3; 3=2; 4=1")
table(peru_data$ONG)
1 2 3 4
234 417 353 107 table(peru_data$P15ST.C)
1 2 3 4
40 254 429 383 library(car)
peru_data$Sindicatos = recode(peru_data$P15ST.C,"1=4;2=3;3=2;4=1")
table(peru_data$Sindicatos)
1 2 3 4
383 429 254 40 table(peru_data$P15ST.D)
1 2 3 4
98 308 442 311 library(car)
peru_data$Media = recode(peru_data$P15ST.D,"1=4;2=3;3=2;4=1")
table(peru_data$Media)
1 2 3 4
311 442 308 98 table(peru_data$P15ST.G)
1 2 3 4
24 234 426 302 library(car)
peru_data$Multi=recode(peru_data$P15ST.G ,"1=4;2=3;3=2;4=1")
table(peru_data$Multi)
1 2 3 4
302 426 234 24 #Luego, con la construccion del indice aditivo (sumar):
peru_data$suma=(peru_data$ONG+peru_data$Sindicatos+peru_data$Media+peru_data$Multi)
summary(peru_data$suma) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
4.000 7.000 8.000 8.435 10.000 16.000 246 minimo 4 maximo 16
#luego de sumar, continuamos según lo que nos pide:
# Convertir del 0 al 100
peru_data$restado=peru_data$suma-4 # resto por el mínimo
peru_data$indicador=(peru_data$restado/12)*100 #divido entre el nuevo máximo
summary(peru_data$indicador) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 25.00 33.33 36.96 50.00 100.00 246 y ahora sí podemos hacer summary pues ya es una variable numerica
- Advertimos NA’s y borramos:
sum(is.na(peru_data$indicador))[1] 246peru_data = peru_data[complete.cases(peru_data$indicador), ]10.1 GRAFICO DE CAJAS (BOXPLOT) E HISTOGRAMA (HIST)
#boxplot(peru_data$indicador)
#hist(peru_data$indicador)
library(ggplot2)
library(plotly)
p1 <- ggplot(peru_data, aes(x = "", y = indicador, color ="")) +
geom_boxplot() + coord_flip() +
theme(legend.position = "top", axis.text.y = element_blank(), panel.background=element_rect(fill = "white", colour = "white")) +
geom_jitter(shape = 16, position = position_jitter(0.2)) +
labs(title = "Indicador", x = "", y ="Index", subtitle = "", caption = "Fuente: Latinobarometro 2020. Elaboración propia.")
ggplotly(p1)Figure 1: Indicador (Latinobarometro 2020).
# HIST:
ggplot(peru_data, aes(x = indicador, color = "")) +
geom_histogram(fill = "white", alpha = 0.5, position = "identity", bins = 30) + #agregar bins = 30 o breaks=seq()
labs(title ="Indicador", y = "", x="Index", subtitle = "", caption = "Fuente: Latinobarometro 2020. Elaboración propia.")+
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background=element_rect(fill = "white", colour = "white"))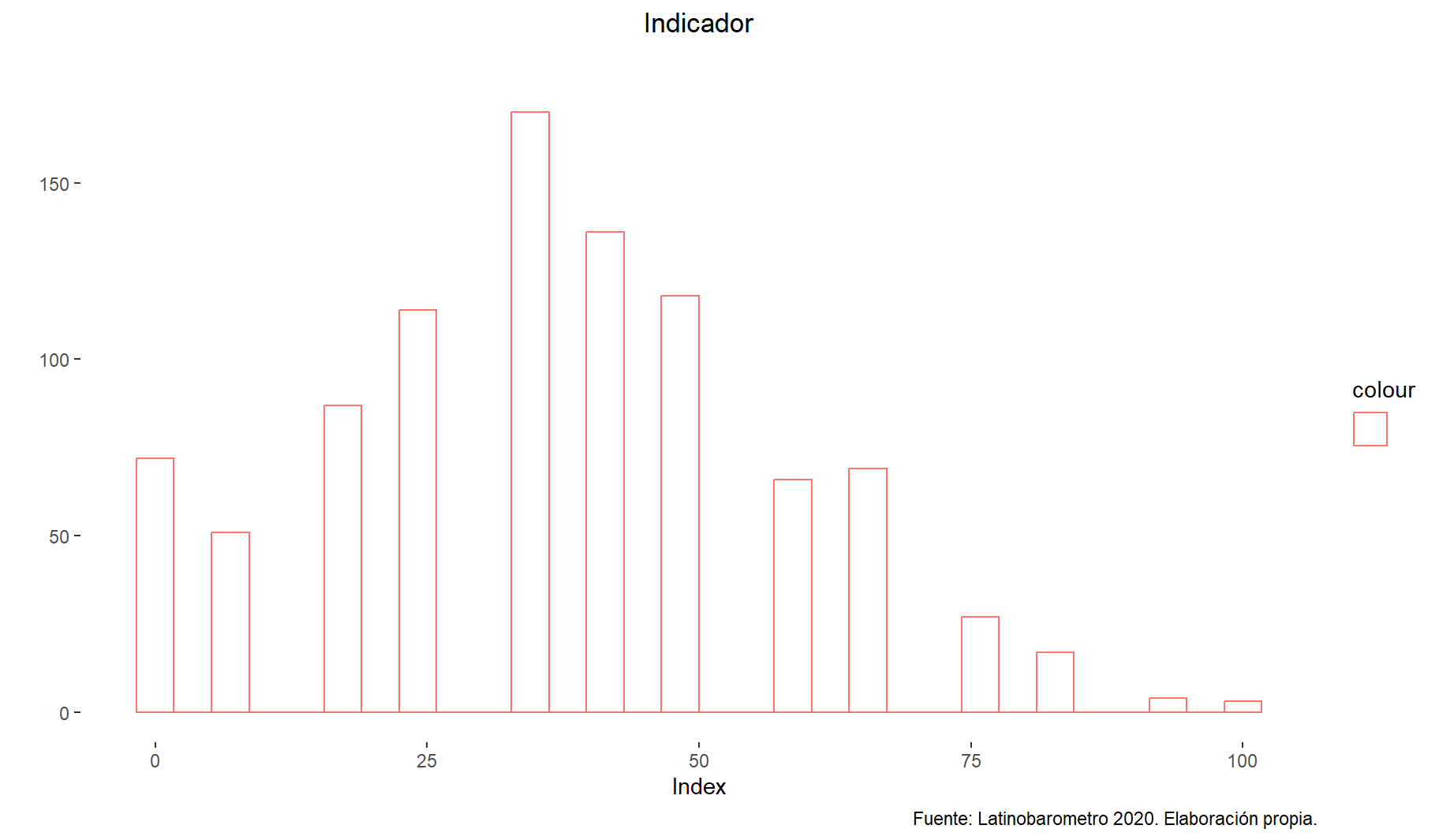
- AQUÍ HACEMOS T.TEST SOLO CON LA VARIABLE NUMERICA, PUES NOS DA EL PROMEDIO y el intervalo de confianza–> lo que nos solicita la pregunta RA:
#Otra forma es más larga
t.test(peru_data$indicador)
One Sample t-test
data: peru_data$indicador
t = 53.998, df = 933, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
35.61263 38.29886
sample estimates:
mean of x
36.95575 10.2 INTERPRETACIÓN:
- La distribución de la variables nos reporta que el indicador de confianza (0-100) es ….., muestra una distribución asimétrica hacia la derecha, es decir, hay mayor concentración de casos en los valores menores.
#El promedio de la confianza es de 36.92. A un 95% de nivel de confianza, el promedio oscila entre 35.58 puntos y 38.25 puntos. #(puntos pues hablamos del indicador!!!)
11 Pregunta 4 (5 puntos)
• Responda si existe diferencia de promedios del indicador de CONFIANZA INSTITUCIONAL DE ORGANIZACIONES DE LA SOCIEDAD CIVIL con respecto a sexo, ideología política (izquierda, centro y derecha) y grupos de edad (jóvenes, adultos, adultos mayores). Elabore un balance general de las diferencias. (5 puntos)
#tenemos que haces estos pasos con cada variable (se usará diferentes pruebas):
#Identificamos: Indicador de confianza (Variable Numérica) - Sexo (Nominal dicotómica). Entonces, usamos La prueba es el T-test. Primero con sexo:
t.test(indicador ~ SEXO, data = peru_data)
Welch Two Sample t-test
data: indicador by SEXO
t = 1.6403, df = 923.72, p-value = 0.1013
alternative hypothesis: true difference in means between group Hombre and group Mujer is not equal to 0
95 percent confidence interval:
-0.4408926 4.9300446
sample estimates:
mean in group Hombre mean in group Mujer
38.01555 35.77098 #INTERPRETACIÓN: #H0: No existe diferencia significativa del promedio de confianza institucional entre hombres y mujeres. #Verifico el p-valor que es 0.08. No rechazo la hipótesis nula.
##A un nivel de confianza del 95%, se podría indicar que no existe diferencia significativa entre los promedios de confianza institucional entre hombres y mujeres. El promedio de hombres es 38.02 y mujeres es 35.69 puntos. El intervalo de confianza de la diferencia de promedios oscila entre -0.34 y 4.99, es decir, que puede tomar el valor 0, no hay diferencia.
#CUANDO EL NIVEL DE CONFIANZA ES DEL 95%. #RECHAZO LA H0, CUANDO EL P-VALOR ES MENOR QUE 0.05 #NO RECHAZO LA H0, CUANDO EL P-VALOR ES MAYOR QUE 0.05
#CUANDO EL NIVEL DE CONFIANZA ES DEL 90%. #RECHAZO LA H0, CUANDO EL P-VALOR ES MENOR QUE 0.1 #NO RECHAZO LA H0, CUANDO EL P-VALOR ES MAYOR QUE 0.1
#CUANDO EL NIVEL DE CONFIANZA ES DEL 99%. #RECHAZO LA H0, CUANDO EL P-VALOR ES MENOR QUE 0.01 #NO RECHAZO LA H0, CUANDO EL P-VALOR ES MAYOR QUE 0.01
11.1 Ahora con ideología política (P18ST). En el cuestionario está del 0 al 10. Entonces, tenemos que recodificar
12 Identificamos que el Indicador de confianza (Variable Numérica)- ideología política (Nominal polinómica), por tanto, usaremos la prueba bivariada es la prueba ANOVA.
table(peru_data$P18ST)
0 1 2 3 4 5 6 7 8 9 10 97
66 38 51 53 71 330 81 54 45 12 66 36 library(car)
peru_data$Ideologia=recode(peru_data$P18ST,
"0:3 = 'Izquierda'; 4:6 = 'Centro'; 7:10 = 'Derecha'; 97= NA")
table(peru_data$Ideologia)
Centro Derecha Izquierda
482 177 208 - Advertimos NA’s y borramos:
sum(is.na(peru_data$Ideologia))[1] 67peru_data = peru_data[complete.cases(peru_data$Ideologia), ]#En este caso tenemos que hacer la prueba anova:
anova1 = aov(indicador ~ Ideologia, data = peru_data)
summary(anova1) Df Sum Sq Mean Sq F value Pr(>F)
Ideologia 2 6015 3007.3 7.052 0.000916 ***
Residuals 864 368430 426.4
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#H0: No existe diferencia significativa del promedio de Confianza de acuerdo a la ideología política de las personas.
TukeyHSD(anova1) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = indicador ~ Ideologia, data = peru_data)
$Ideologia
diff lwr upr p adj
Derecha-Centro 0.8436482 -3.417294 5.104590 0.8877537
Izquierda-Centro -5.8939116 -9.915915 -1.871908 0.0017604
Izquierda-Derecha -6.7375598 -11.695316 -1.779804 0.004195812.1 BOXPLOT
library(ggplot2)
library(plotly)
boxplot <- ggplot(peru_data, aes(y = indicador,
x = Ideologia,fill=factor(Ideologia))) +
geom_boxplot() + xlab("Ideologia") + ylab("Indicador")
ggplotly(boxplot)library(gplots)
plotmeans(indicador ~ Ideologia, data = peru_data,
p = 0.95,
main= "Mean Plot \n with 95% CI")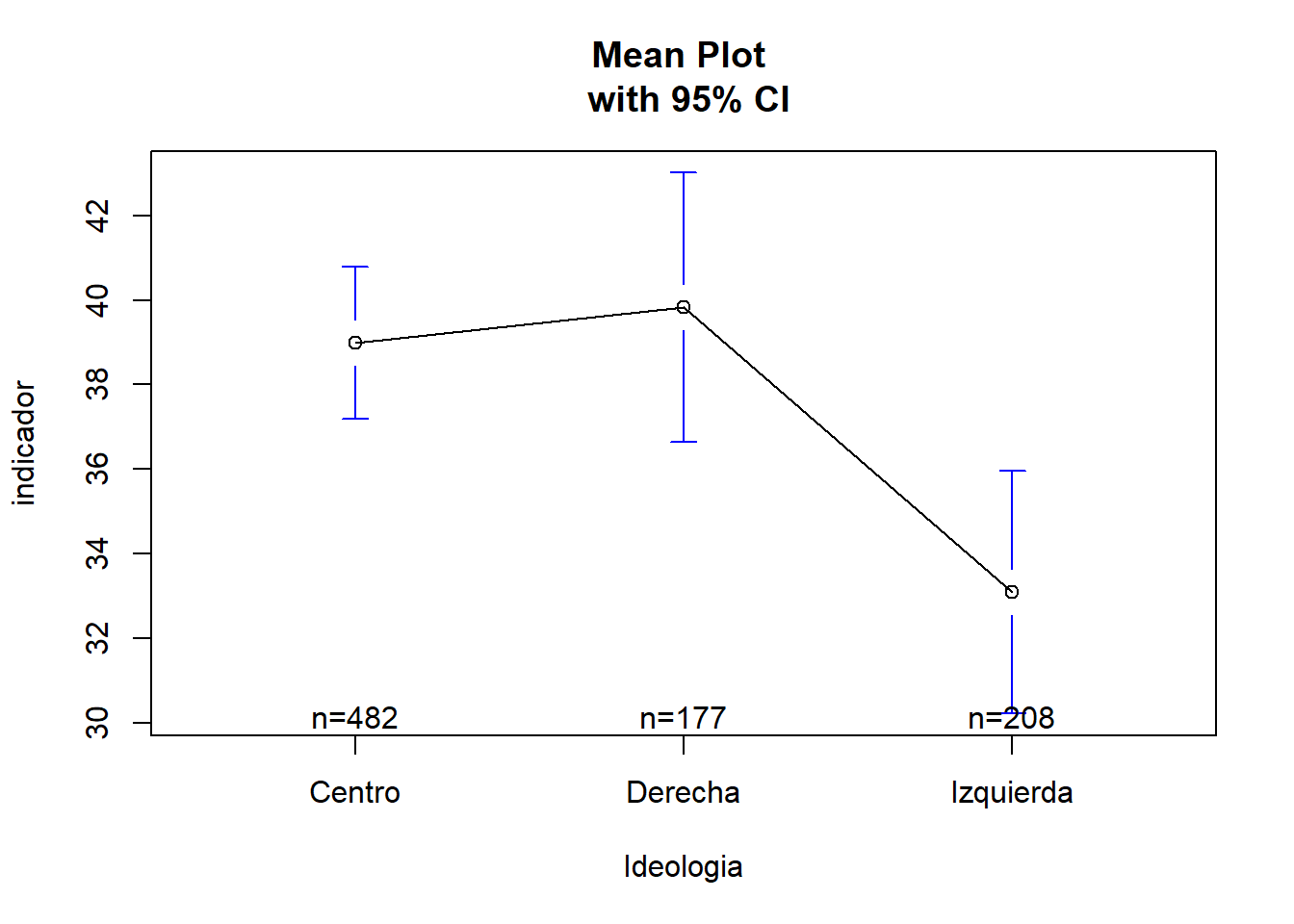
12.2 INTEEPRETACIÓN:
- A nivel de confianza del 95%, se podría afirmar que existe diferencia significativa del promedio de Confianza de acuerdo a la ideología política de las personas. De acuerdo a la prueba Tukey, se observa que existe diferencia entre los promedios de las personas con tendencia política de centro con las de izquierda (), y a su vez, las personas de izquierda con las de ideología de derecha.
Ahora con - Indicador de confianza (Variable Numérica)- Grupos de edad ( Ordinal) La prueba bivariada es la prueba ANOVA.
13 Pregunta 5 (2 puntos)
#¿Existe alguna relación entre su evaluación de la actual situación económica (P5STGBS) y su satisfacción con la democracia (P11STGBS.A)?
#Haremos #Dos variables ordinales … Prueba Chi-cuadrado #Definir el tipo de relación: Simétrica #Sentido y la intensidad (Gamma)
14 Pregunta 6 (2 puntos)
¿Existe asociación entre la formar parte de un grupo discriminado (P57ST) y la percepción de probabilidad de sufrir repercusiones por opiniones políticas? (P60N.B) Si es así, describa la asociación.
#Haremos #Prueba Chi-cuadrado #Definir el tipo de relación: Asimétrica #Intensidad
- Viendo el cuestionario y su estructura:
str(peru_data$P57ST) # Nominal <- variable independiente num [1:867] 2 2 2 1 2 2 2 1 2 2 ...str(peru_data$P60N.B) # Nominal sí, no, NS/NR <- variable dependiente num [1:867] 2 2 1 1 2 1 1 2 1 NA ...- Formateo:
peru_data$P57ST = as.factor(peru_data$P57ST)
peru_data$P57ST = factor(peru_data$P57ST,
levels = levels(peru_data$P57ST),
labels = c("Sí","No"),
ordered = F)
#table(peru_data$P57ST)peru_data$P60N.B = as.factor(peru_data$P60N.B)
peru_data$P60N.B = factor(peru_data$P60N.B,
levels = levels(peru_data$P60N.B),
labels = c("Sí","No"),
ordered = F)
table(peru_data$P60N.B)
Sí No
526 326 - Advertimos NA’s y borramos:
sum(is.na(peru_data$P57ST)) # Borrar 6 NA's[1] 6peru_data = peru_data[complete.cases(peru_data$P57ST), ]
sum(is.na(peru_data$P60N.B)) # 15 NA's[1] 15peru_data = peru_data[complete.cases(peru_data$P60N.B), ]addmargins(table(peru_data$P57ST, peru_data$P60N.B))
Sí No Sum
Sí 140 53 193
No 381 272 653
Sum 521 325 846chisq.test(peru_data$P57ST, peru_data$P60N.B)
Pearson's Chi-squared test with Yates' continuity correction
data: peru_data$P57ST and peru_data$P60N.B
X-squared = 12.091, df = 1, p-value = 0.000506615 Pregunta 7 (2 puntos)
• ¿Existe asociación entre la percepción de garantía de justa distribución de la riqueza (P47ST.F) y la clase social (S1)? Si es así, describa la asociación.
#haremos #Prueba Chi-cuadrado #Definir el tipo de relación: Asimétrica #Intensidad
- Viendo el cuestionario y su estructura:
str(peru_data$P47ST.F) # Ordinal <- variable independiente num [1:846] 3 4 1 3 3 3 2 3 2 3 ...str(peru_data$S1) # Nominal sí, no, NS/NR <- variable dependiente num [1:846] 3 5 4 3 5 3 5 4 4 5 ...- Formateo:
#table(peru_data$P47ST.F)
library(car)
peru_data$P47ST.F = recode(peru_data$P47ST.F,
"1= 4; 2= 3; 3= 2; 4= 1") # Recodificando
#table(peru_data$P47ST.F)peru_data$S1[peru_data$S1 == 8]= NA # Revisando el codebook, encontramos que se ha digitado un numero 8, mejor lo convertimos NA y luego lo eliminamos.table(peru_data$S1)
1 2 3 4 5
17 65 310 237 196 library(car)
peru_data$S1 = recode(peru_data$S1,
"1= 5; 2= 4; 3= 3; 4= 2; 5 = 1" ) # Recodificando
table(peru_data$S1)
1 2 3 4 5
196 237 310 65 17 peru_data$P47ST.F = as.factor(peru_data$P47ST.F)
peru_data$P47ST.F = factor(peru_data$P47ST.F,
levels = levels(peru_data$P47ST.F),
labels = c("garantizada","algo", "poco", "para_nada"),
ordered = T)
table(peru_data$P47ST.F)
garantizada algo poco para_nada
98 368 294 84 peru_data$S1 = as.factor(peru_data$S1)
peru_data$S1 = factor(peru_data$S1,
levels = levels(peru_data$S1),
labels = c("alta","media_alta", "media", "media_baja", "baja"),
ordered = T)
table(peru_data$S1)
alta media_alta media media_baja baja
196 237 310 65 17 - Advertimos NA’s y borramos:
sum(is.na(peru_data$P47ST.F)) # Borrar 2 NA's[1] 2peru_data = peru_data[complete.cases(peru_data$P47ST.F), ]
sum(is.na(peru_data$S1)) # 21 NA's[1] 21peru_data = peru_data[complete.cases(peru_data$S1), ]