#getwd()
#setwd(" ")
# Revisar el diccionario, la metadata, cuestionario, etc...
library("rio")
datalapop =import("./data/s2/LAPOP_PERU_2019.dta")
#names(datalapop) # Colocar en el Console
#str(datalapop)
#class(datalapop)2 Ejercicio estadistica descriptiva
Co-author: Luis Valverde
3 q1 <- sexo (Variable Categórica nominal)
#str(datalapop$q1) # Estructura de la variable- formateo
datalapop$q1 = as.factor(datalapop$q1) # as.factor --> A formato a c. nominal
# El comando `factor` no sirve para dar nombre a las etiquetas de la
# variable nominal sexo
datalapop$q1 = factor(datalapop$q1, # $ --> Pertenencia
levels = levels(datalapop$q1), # Niveles de escala
labels = c("Hombre","Mujer"), # Etiqueta de los valores/niveles
ordered = FALSE) # ordered: las categorias están ordenadas.
# En este caso FALSE para señalar que es nominal y la
# variable sexo no presenta un orden
#str(datalapop$q1) # Comprobamos otra vez la estructuratable(datalapop$q1) # tabla de frecuencia respecto al sexo
Hombre Mujer
758 762 #prop.table(table(data$var))
prop.table(table(datalapop$q1))*100 # frecuencias relativas porcentuales
Hombre Mujer
49.86842 50.13158 library(Hmisc)
describe(datalapop$q1) # Mejor opcion para obtener la modadatalapop$q1
n missing distinct
1520 1 2
Value Hombre Mujer
Frequency 758 762
Proportion 0.499 0.501# Otras opciones para obtener la moda:
#summary(datalapop$q1)
library(DescTools)
#Mode(datalapop$q1,na.rm = T)3.1 GRAFICO DE BARRAS (BARPLOT)
# creamos un objeto que contenga la tabla de frecuencias de la variable:
grafico1 <- table(datalapop$q1)
grafico1 = as.data.frame(grafico1) #dataframe
colnames(grafico1) = c("Reg","Freq") #renombrar
library(ggplot2)
bp = ggplot(grafico1, aes(x = reorder(Reg, Freq), y = Freq, fill = Reg)) +
# aes(x = reorder(Reg, Freq) -> así para ordenar las barras ascendentemente
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Genero", y = "Frecuencias", x = "Categorías", subtitle = "",
caption = "Fuente: Elaboración propia. LAPOP: Perú, 2019") +
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background = element_rect(fill = "white", colour = "white")) +
geom_text(aes(label = Freq), # Frecuencias en las barras
vjust = 0.5, color = "black", size = 5)
bp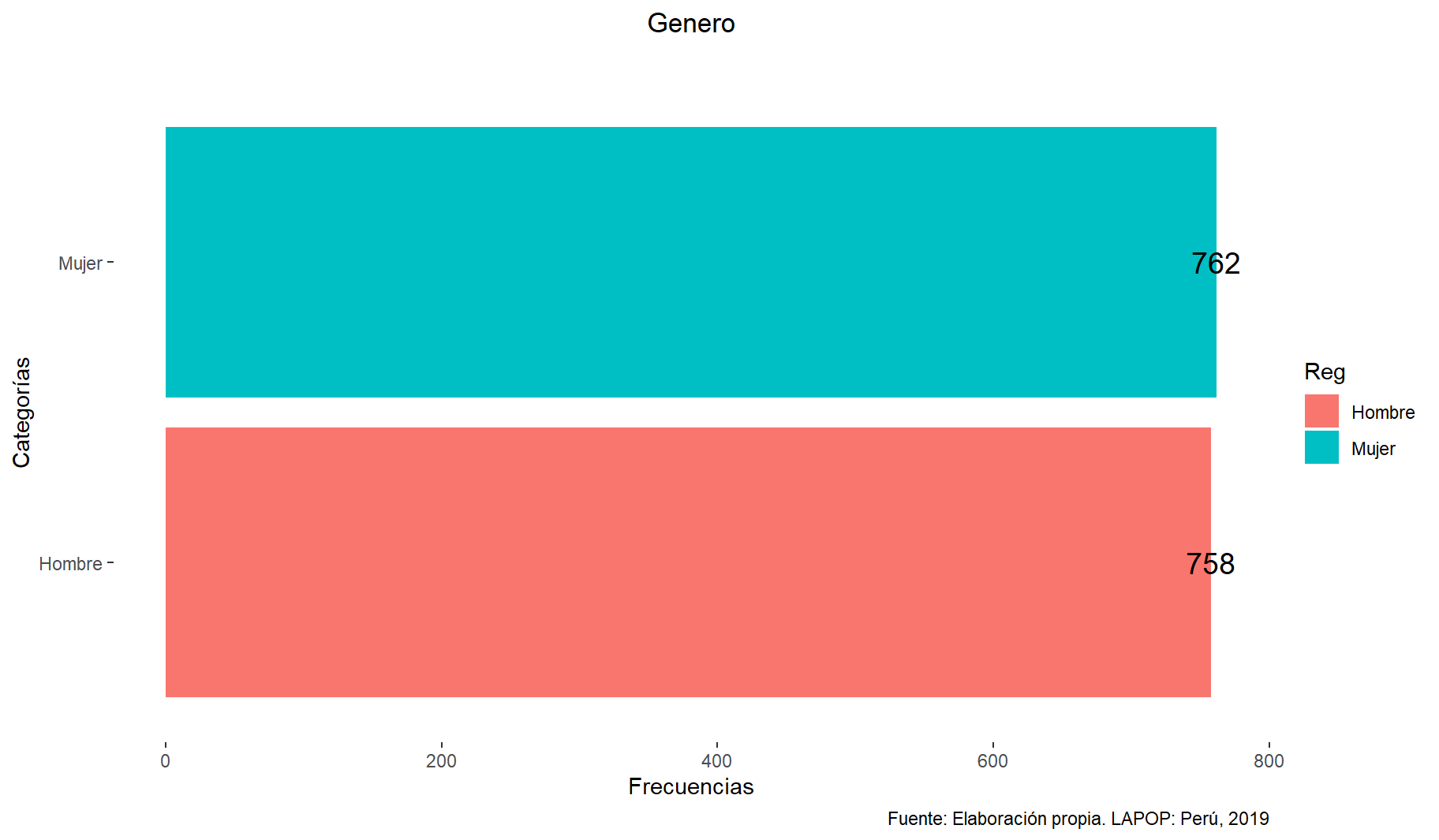
INTERPRETACION:
4 2. sd6new2 <- Satisalud <- variable nivel de satisfacción con la salud (variable categorica ordinal)
#str(datalapop$sd6new2) # estructura de la variable- formateo
# as.factor -> a formato c. nominal:
#datalapop$sd6new2 = as.factor(datalapop$sd6new2)
# Puedo cambiar el nombre de la variable para un mejor entendimiento:
datalapop$Satisalud = as.factor(datalapop$sd6new2)
# Nota: se estaría creando una nueva variable (no se está chancando como en el
# codigo anterior), es decir, se esta creando un nuevo objeto.
# El comando factor no sirve para dar nombre a las etiquetas de la
# variable nominal sexo:
datalapop$Satisalud = factor(datalapop$Satisalud, # $ --> pertenencia
levels = levels(datalapop$Satisalud), #niveles de escala
labels = c("Muy satisfecho","Satisfecho","Insatisfecho",
"Muy insatisfecho"), # Etiqueta de los valores/niveles
ordered = T) # ordered: las categorias están ordenadas.
# En este caso TRUE para señalar que es ordinal. presenta un orden.
#str(datalapop$Satisalud) # comprobamos otra vez la estructurasum(is.na(datalapop$Satisalud))[1] 31datalapop = datalapop[complete.cases(datalapop$Satisalud), ]table(datalapop$Satisalud) # Tabla respecto al sexo
Muy satisfecho Satisfecho Insatisfecho Muy insatisfecho
50 418 744 278 prop.table(table(datalapop$Satisalud))*100 # frecuencias relativas porcentuales
Muy satisfecho Satisfecho Insatisfecho Muy insatisfecho
3.355705 28.053691 49.932886 18.657718 library(Hmisc)
describe(datalapop$Satisalud)datalapop$Satisalud
n missing distinct
1490 0 4
Value Muy satisfecho Satisfecho Insatisfecho Muy insatisfecho
Frequency 50 418 744 278
Proportion 0.034 0.281 0.499 0.187- Gráficos: BOXPLOT: ORDINAL Y NUMERICA: PREFERIBLE PARA 7 NIVELES HACIA ARRIBA. Esto es necesario para la interpretacion: el boxplot se interpreta en base a las posiciones de los cuartiles q1 q2 q3.
4.1 GRAFICO DE BARRAS (BARPLOT)
# creamos un objeto que contenga la tabla de frecuencias de la variable:
grafico2 <- table(datalapop$Satisalud)
grafico2 = as.data.frame(grafico2) # dataframe
colnames(grafico2) = c("Reg","Freq") # renombrar
library(ggplot2)
bp = ggplot(grafico2, aes(x = reorder(Reg, Freq), y = Freq, fill = Reg)) +
#aes(x=reorder(Reg,Freq) -> así para ordenar las barras ascendentemente
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Nivel de satisfaccion con la salud", y = "Frecuencias",
x = "Categorías", subtitle = "",
caption = "Fuente: Elaboracion propia. LAPOP 2019") +
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background = element_rect(fill = "white", colour = "white")) +
geom_text(aes(label = Freq), # Frecuencias en las barras
vjust = 0.5, color = "black", size = 5)
bp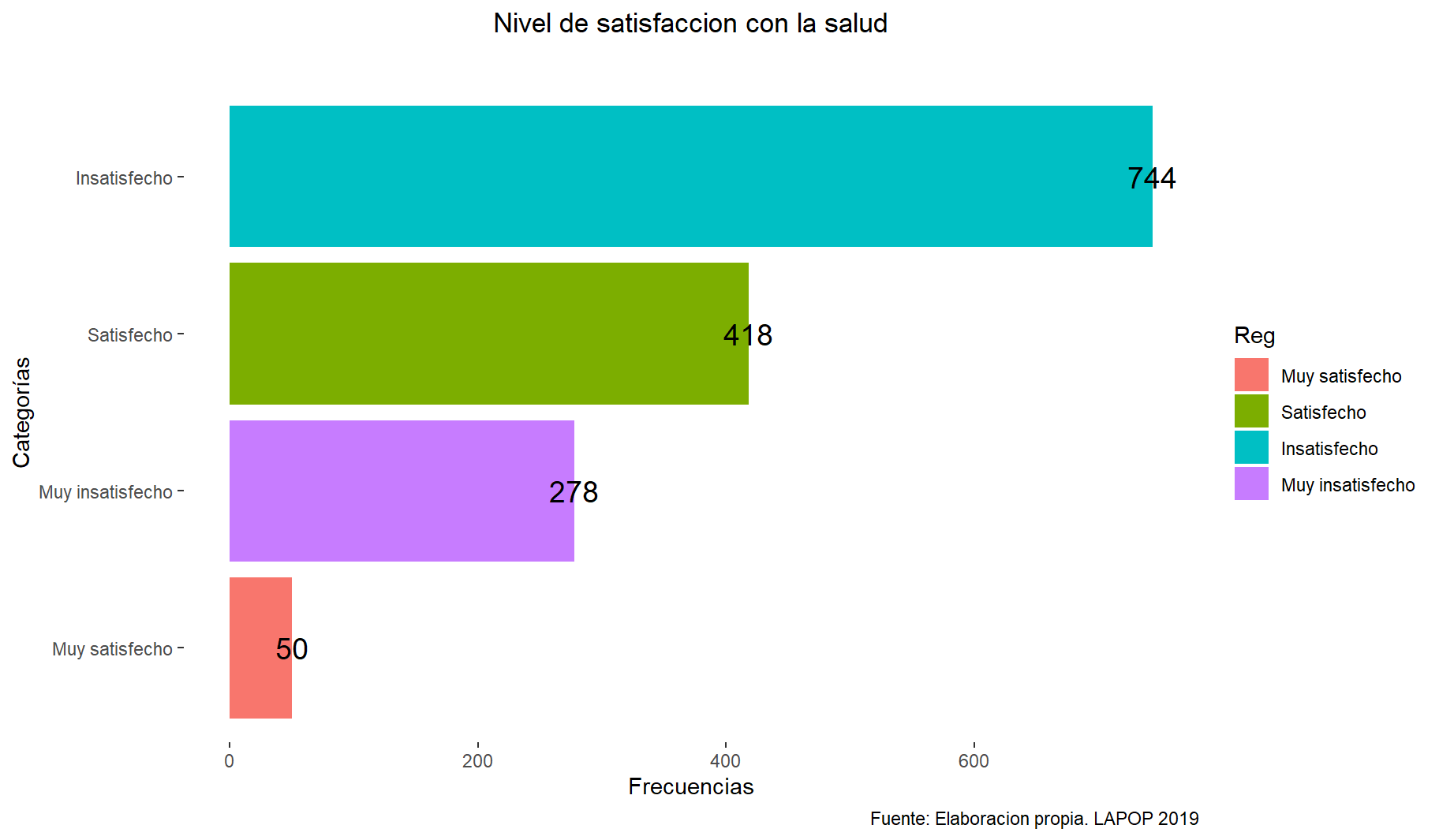
4.2 GRAFICO DE CAJAS (BOXPLOT)
# boxplot(datalapop$Satisalud) # boxplot basico de R
library(ggplot2)
library(plotly)
p2 <- ggplot(grafico2, aes(x = Reg, y = Freq, color = Reg)) +
geom_boxplot() +
coord_flip() + #Volteamos el gráfico
theme(legend.position = "top", axis.text.y = element_blank(),
panel.background=element_rect(fill = "white",
colour = "white")) + # Quitamos categorías
geom_jitter(shape = 16,
position = position_jitter(0.2)) + # Agregamos los casos como puntos
labs(title = "Nivel de satisfaccion con la salud", x = "", y = "Index")
ggplotly(p2)Figure 2: Nivel de satisfaccion con la salud (LAPOP 2019).
5 3. q2 <- Edad de los encuestados (variable numerica).
- Formateo
datalapop$q2 = as.numeric(datalapop$q2) #as.numeric -> a formato a v. numerica
#str(datalapop$q2)- Procedemos a la descripcion:
6 Medidas de centralidad
mean(datalapop$q2, na.rm = T) # media[1] 38.65883library(DescTools)
Median(datalapop$q2, na.rm = T) # Mediana[1] 36Mode(datalapop$q2, na.rm = T) # Moda[1] 30
attr(,"freq")
[1] 85describe(datalapop$q2) # percentiles y valores altos y bajos para sacar outliersdatalapop$q2
n missing distinct Info Mean Gmd .05 .10
1489 1 68 0.999 38.66 17.41 19 20
.25 .50 .75 .90 .95
26 36 48 61 68
lowest : 18 19 20 21 22, highest: 83 84 85 90 91summary(datalapop$q2) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
18.00 26.00 36.00 38.66 48.00 91.00 1 - Edad de los encuestados está entre los 18 y 91 años
- El 50% de los casos tiene al menos 36 años o el otro 50% está por encima de los 36 años
- el promedio es 38 años
- primer cuartil
- el 75% de los encuestados tiene hasta/por lo menos 49 años
# otra opcion al summary:
describe(datalapop$q2) # percentiles y los valores (extremos) bajos y altosdatalapop$q2
n missing distinct Info Mean Gmd .05 .10
1489 1 68 0.999 38.66 17.41 19 20
.25 .50 .75 .90 .95
26 36 48 61 68
lowest : 18 19 20 21 22, highest: 83 84 85 90 91- Podemos calcular estos valores extremos:
# valores extremos
IR = 49-26
valorextremosuperior = 49+1.5*IR
valorextremosuperior[1] 83.5#v alores extremos superior
valorextremoinferior = 26-1.5*IR
valorextremoinferior[1] -8.5Entonces, todos los valores mayores a 83 son los valores extremos hacia arriba.
sale negativo. entonces, no hay valores extremos hacia abajo. en efecto, en concordancia con Describe, el menor tiene 18 años
Grafico fachero:
library(ggplot2)
library(plotly) # Graficos dinamicos
p3 <- ggplot(datalapop, aes(x = "", y = q2, color = "")) +
geom_boxplot() + coord_flip() + # Volteamos el gráfico
theme(legend.position = "top", axis.text.y = element_blank(),
panel.background = element_rect(fill = "white", colour = "white")
) + # Quitamos categorías
geom_jitter(shape=16,position = position_jitter(0.2)
) + # Agregamos los casos como puntos
labs(title = "Encuestados según edad ", x = "", y = "Index", subtitle = "",
caption = "LAPOP 2019")
ggplotly(p3)Figure 3: Encuestados según edad (LAPOP 2019).
# HIST:
ggplot(datalapop, aes(x = q2, color = "")) +
geom_histogram(fill = "white", alpha = 0.5, position="identity") +
labs(title = "Encuestados según edad", y = "", x = "Index", subtitle = "",
caption = "LAPOP 2019") +
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background = element_rect(fill = "white", colour = "white"))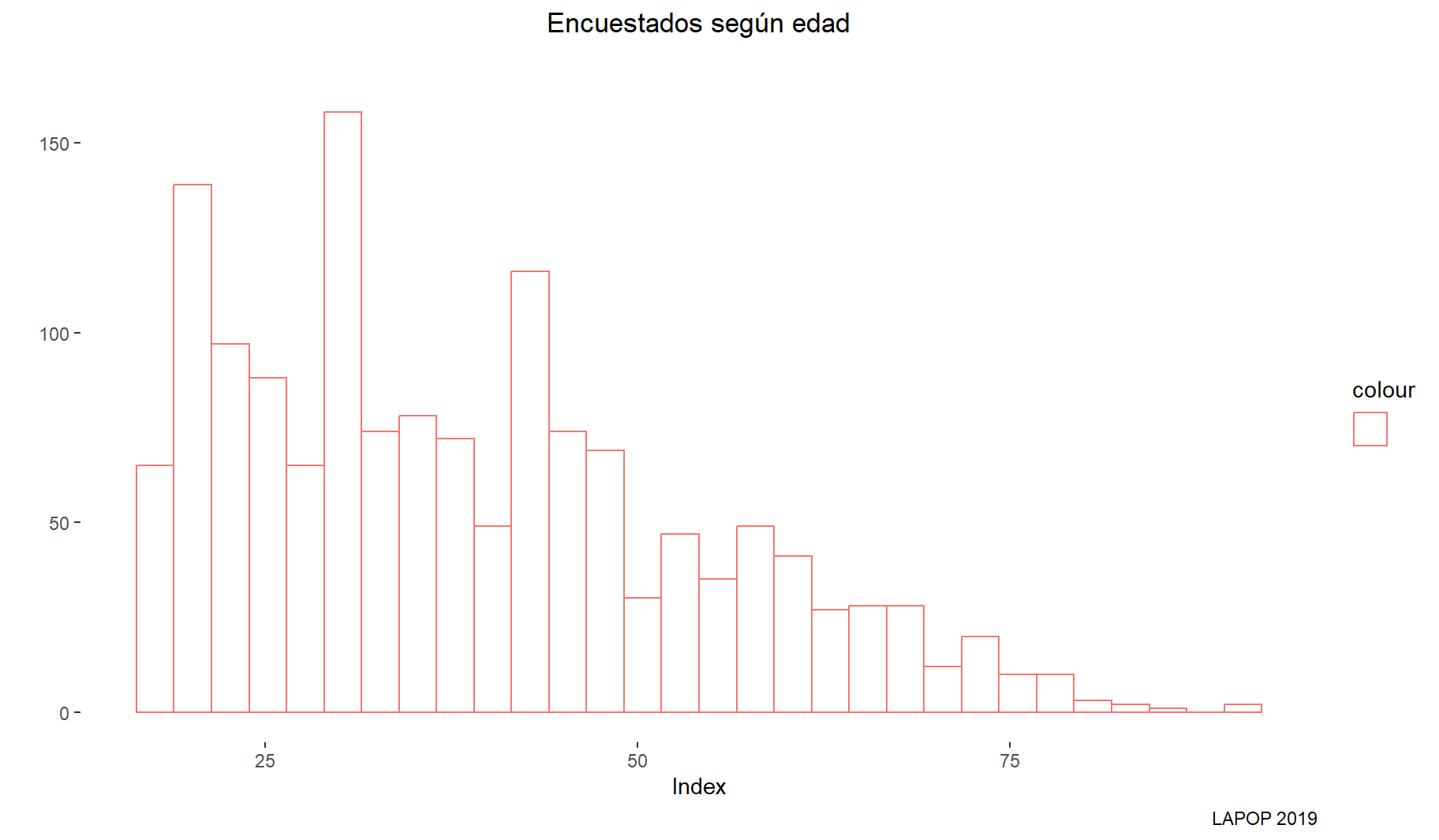
6.1 INTERPRETACION:
el 75% de los datos se acumulan al parecer debajo de los 49 años
el 50% de los encuestados está debajo de los 36 años
La línea de dentro de la caja representa la mediana, la caja representa en la parte inferior el cuartil 1 y el cuartil 3, es decir el 50% de los valores de la variable se encuentran dentro de la caja, y las barras representan el valor máximo y mínimo sin los outliers, que son los puntos negros
asimetria positiva. sesgo a la derecha los datos se concentran entre los mas jovenes
6.1.1 Medidas de centralidad
library(DescTools)
Mode(datalapop$q1, na.rm = T)[1] Mujer
attr(,"freq")
[1] 745
Levels: Hombre Mujerlibrary(DescTools)
Mode(datalapop$Satisalud, na.rm = T) # en este caso es 744[1] Insatisfecho
attr(,"freq")
[1] 744
Levels: Muy satisfecho < Satisfecho < Insatisfecho < Muy insatisfechoMedian(datalapop$Satisalud, na.rm = T) # en este caso es insatisfecho[1] Insatisfecho
Levels: Muy satisfecho < Satisfecho < Insatisfecho < Muy insatisfecholibrary(DescTools)
Mode(datalapop$q2, na.rm = T) # hay dos modas: 30 (personas) y 85 años[1] 30
attr(,"freq")
[1] 85# con una tabla podemos advertir cuantas personas personas tienen 85 años:
table(datalapop$q2)
18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
65 47 44 48 47 50 25 35 28 33 32 45 85 28 41 33 26 28 24 22 27 23 32 17 34 37
44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69
45 47 27 20 29 20 21 9 14 13 20 19 16 16 15 18 27 14 12 9 6 17 11 9 11 8
70 71 72 73 74 75 76 77 78 79 81 83 84 85 90 91
9 3 9 9 2 4 6 2 4 4 3 1 1 1 1 1 Median(datalapop$q2, na.rm = T) #--> en este caso es 36[1] 36mean(datalapop$q2, na.rm = T)[1] 38.65883describe(datalapop$q2)datalapop$q2
n missing distinct Info Mean Gmd .05 .10
1489 1 68 0.999 38.66 17.41 19 20
.25 .50 .75 .90 .95
26 36 48 61 68
lowest : 18 19 20 21 22, highest: 83 84 85 90 917 Medidas de dispersion para una variable numerica
min(datalapop$q2, na.rm = T) # na.rm= T no considera los valores perdidos[1] 18max(datalapop$q2, na.rm = T)[1] 91range(datalapop$q2, na.rm = T)[1] 18 91quantile(datalapop$q2, na.rm = T) 0% 25% 50% 75% 100%
18 26 36 48 91 IQR(datalapop$q2, na.rm = T)[1] 22##Medidas de dispersión
var(datalapop$q2, na.rm = T) #varianza[1] 239.8271sd(datalapop$q2, na.rm = T) #desviación[1] 15.48635- ambas son altas. parece indicar que hay bastante sesgo
library(moments)
skewness(datalapop$q2, na.rm = T) #asimetría[1] 0.6491672kurtosis(datalapop$q2, na.rm = T) #curtosis[1] 2.641518- asimetria positiva. sesgo a la derecha.
- leptocurtica.
8 # Actividad en R
- Revisa el cuestionario de LAPOP (PAIDEIA) y realiza los estadísticos descriptivos para una variable nominal, una ordinal y una numérica.
DESARROLLO:
9 1. Variable Categórica nominal: np1 <- Asistencia a una reunión municipal
datalapop$np1 = as.factor(datalapop$np1)
#str(datalapop$np1)datalapop$np1 = factor(datalapop$np1,
levels = levels(datalapop$np1),
labels = c("Asistió","No Asistió"),
ordered = F)
#str(datalapop$np1) - Tablas respecto a la asistencia a una reunión municipal en los últimos 12 meses
table(datalapop$np1)
Asistió No Asistió
180 1303 prop.table(table(datalapop$np1)) * 100
Asistió No Asistió
12.13756 87.86244 library(Hmisc)
describe(datalapop$np1)datalapop$np1
n missing distinct
1483 7 2
Value Asistió No Asistió
Frequency 180 1303
Proportion 0.121 0.879Gráficas: Pie y barras
# No recomendado: PIE:
# pie(table(datalapop$np1), col = rainbow(7),
# main = "Asistencia a las reuniones municipales en los últimos 12 meses")
# tabla = round(prop.table(table(datalapop$np1)) * 100, 2)
# pie(tabla, labels = paste0(tabla, "%"))# Creamos un objeto que contenga la tabla de frecuencias de la variable:
grafico4 <- table(datalapop$np1)
grafico4 = as.data.frame(grafico4) # dataframe
colnames(grafico4) = c("Reg","Freq") # renombrar
library(ggplot2)
bp4 = ggplot(grafico4, aes(x = reorder(Reg, Freq), y = Freq, fill = Reg)) +
#aes(x=reorder(Reg,Freq) -> así para ordenar las barras ascendentemente
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Asistencia a las reuniones municipales en los últimos 12 meses",
y = "Frecuencias", x = "Categorías")+
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background = element_rect(fill = "white", colour = "white")) +
geom_text(aes(label = Freq), vjust=0.5, color = "gray",
size = 5) #Frecuencias en las barras
bp4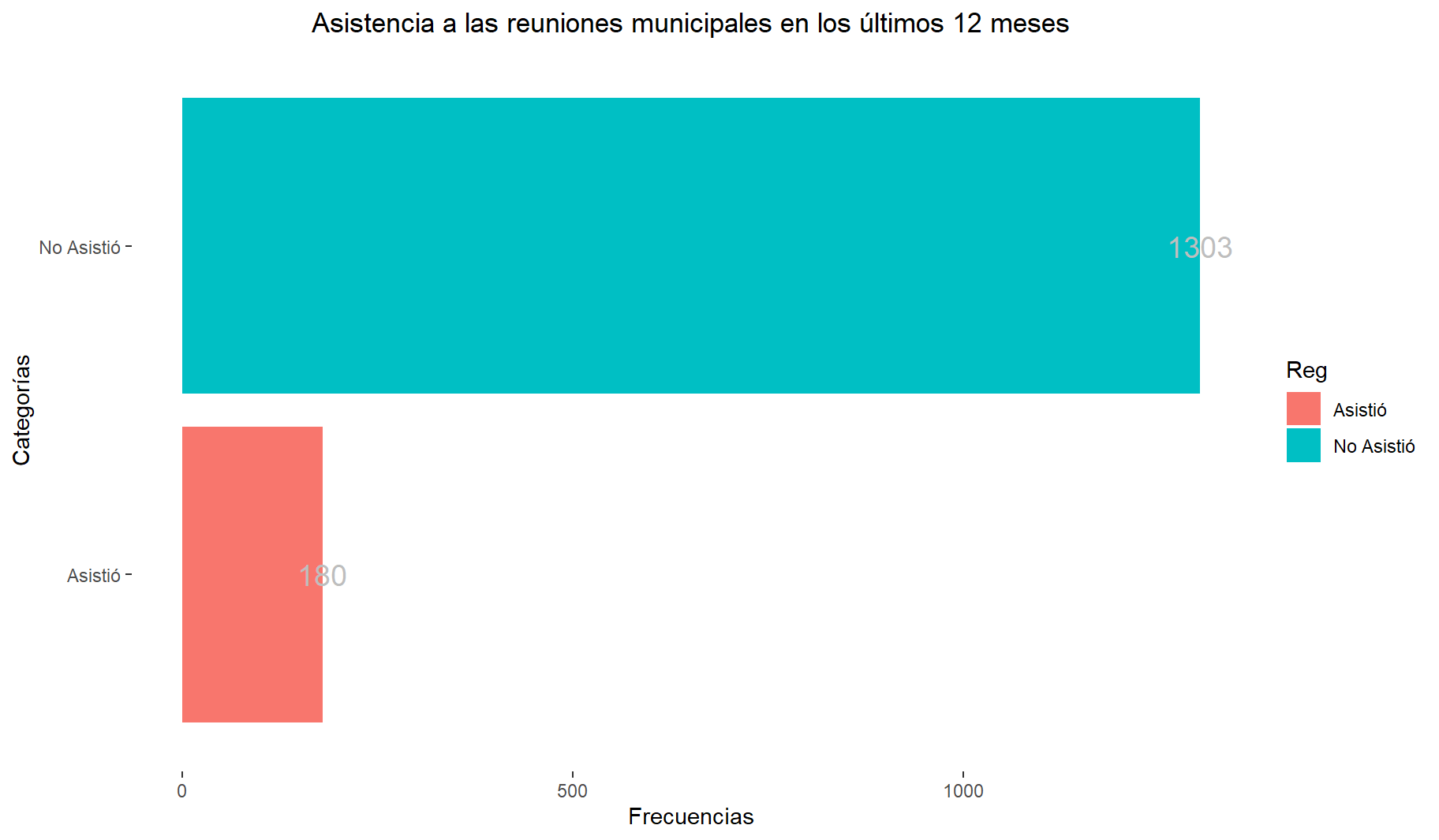
INTERPRETACION: + La mayoría de encuestados no asistió a un cabildo abierto o a una sesión municipal durante los últimos doce meses. + En particular, el 87.85% de los encuestados no asistió a un cabildo abierto o a una sesión municipal durante los últimos doce meses, mientras que solo un 12.15% sí lo hizo.
10 Variable Categórica ordinal: m1 -> Percepción respecto a la labor del presidente Vizcarra.
datalapop$m1 = as.factor(datalapop$m1)
datalapop$m1 = factor(datalapop$m1,
levels = levels(datalapop$m1),
labels = c("Muy bueno", "Bueno", "Regular",
"Malo", "Muy malo"),
ordered = T)
#str(datalapop$m1)- Tablas sobre la percepción respecto a la labor del presidente Vizcarra.
table(datalapop$m1)
Muy bueno Bueno Regular Malo Muy malo
56 519 742 116 42 prop.table(table(datalapop$m1))*100
Muy bueno Bueno Regular Malo Muy malo
3.796610 35.186441 50.305085 7.864407 2.847458 library(Hmisc)
describe(datalapop$m1)datalapop$m1
n missing distinct
1475 15 5
Value Muy bueno Bueno Regular Malo Muy malo
Frequency 56 519 742 116 42
Proportion 0.038 0.352 0.503 0.079 0.028- Graficas: Barras y boxplot
# creamos un objeto que contenga la tabla de frecuencias de la variable:
grafico5 <- table(datalapop$m1)
grafico5 = as.data.frame(grafico5) # dataframe
colnames(grafico5) = c("Reg","Freq") # renombrar
# Grafico basico de R:
# barplot(table(datalapop$m1), col = "darkblue", xlab = NULL,
# ylab = "Conteo de encuestados", main =
# "Percepción de satisfacción respecto a la labor del presidente Vizcarra")
library(ggplot2)
bp4 = ggplot(grafico5, aes(x = reorder(Reg, Freq), y = Freq, fill = Reg)) +
#aes(x=reorder(Reg,Freq) --> así para ordenar las barras ascendentemente
geom_bar(stat = "identity") +
coord_flip() +
labs(title =
"Percepción de satisfacción respecto a la labor del presidente Vizcarra",
y = "Frecuencias", x = "Categorías") +
theme(plot.title = element_text(hjust = 0.5)
) +
theme(panel.background = element_rect(fill = "white", colour = "white")
) +
geom_text(aes(label = Freq), vjust = 0.5, color = "gray",
size = 5) #Frecuencias en las barras
bp4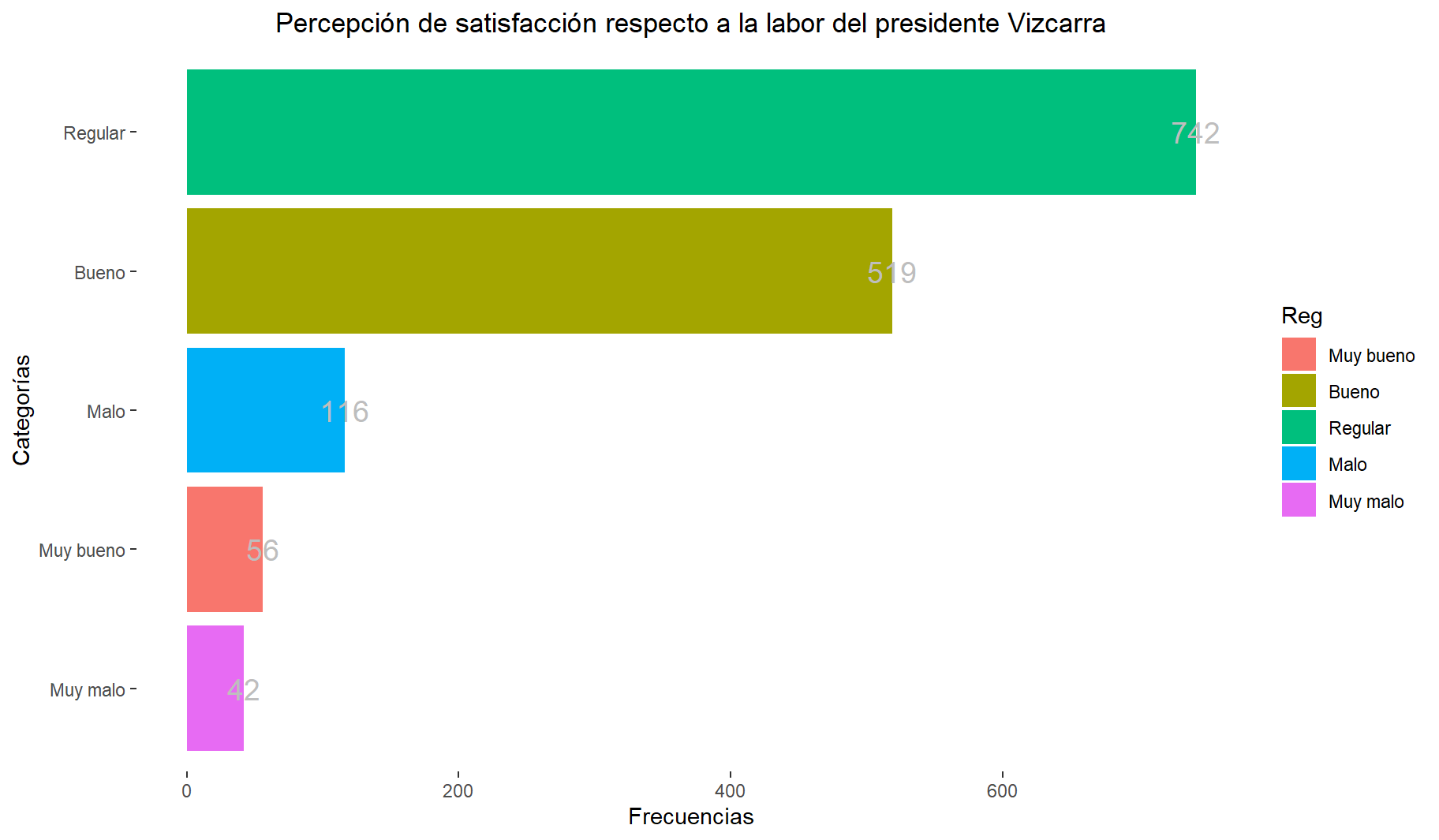
library(plotly)
p5 <- #boxplot(datalapop$m1, col = "pink") # boxplot basico de R
ggplot(datalapop, aes(x="", y=m1, color ="")) +
geom_boxplot() +
coord_flip() + # Volteamos el gráfico
theme(legend.position = "top", axis.text.y = element_blank(),
panel.background = element_rect(fill = "white", colour = "white")
) + #Quitamos categorías
geom_jitter(shape = 16, position = position_jitter(0.2)
) + #Agregamos los casos como puntos
labs(title =
"Percepción de satisfacción respecto a la labor del presidente Vizcarra",
x = "", y = "Index")
ggplotly(p5)10.1 INTERPRETACION:
- La mayoría de personas considera que la labor del presidente Vizcarra ha sido regular.
- El 2.90% de las personas considera que la labor del presidente vizcarra ha sido muy mala, mientras que el 3.79 considera que fue muy buena. En particular, el 50.27% de los encuestados, es decir, la mayoría considera que su labor fue regular.
11 Variable numérica: PSC8 <- Horas de agua al día tiene cuando tiene el servicio
datalapop$psc8 = as.numeric(datalapop$psc8)
#str(datalapop$psc8)sum(is.na(datalapop$psc8)) [1] 317datalapop = datalapop[complete.cases(datalapop$psc8),]summary(datalapop$psc8) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 6.00 24.00 16.38 24.00 24.00 IR=24-6
Valorextremosuperior=24+1.5*IR
Valorextremosuperior[1] 51Valorextremoinferior=6-1.5*IR
Valorextremoinferior[1] -21describe(datalapop$psc8)datalapop$psc8
n missing distinct Info Mean Gmd .05 .10
1173 0 24 0.829 16.38 9.563 2.0 2.2
.25 .50 .75 .90 .95
6.0 24.0 24.0 24.0 24.0
lowest : 1 2 3 4 5, highest: 20 21 22 23 2411.1 Gráficas: boxplot e histograma
#boxplot(datalapop$psc8) #Grafica basica de R
p6 <- ggplot(datalapop, aes(x = "", y = psc8, color = "")) +
geom_boxplot() +
coord_flip() + #Volteamos el gráfico
theme(legend.position = "top", axis.text.y = element_blank(),
panel.background = element_rect(fill = "white", colour = "white")
) + #Quitamos categorías
geom_jitter(shape = 16, position = position_jitter(0.2)
) + # Agregamos los casos como puntos
labs(title = "Horas de agua al día cuando cuenta con el servicio",
x = "", y = "Index")
ggplotly(p6)Figure 1: Docentes según sexo (ENDO 2020).
# HIST:
#hist(datalapop$psc8) # basico de R
ggplot(datalapop, aes(x = psc8, color = "")) +
geom_histogram(fill = "white", alpha = 0.5, position = "identity") +
labs(title = "Horas de agua al día cuando cuenta con el servicio",
y = "", x = "Index")+
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background = element_rect(fill = "white", colour = "white"))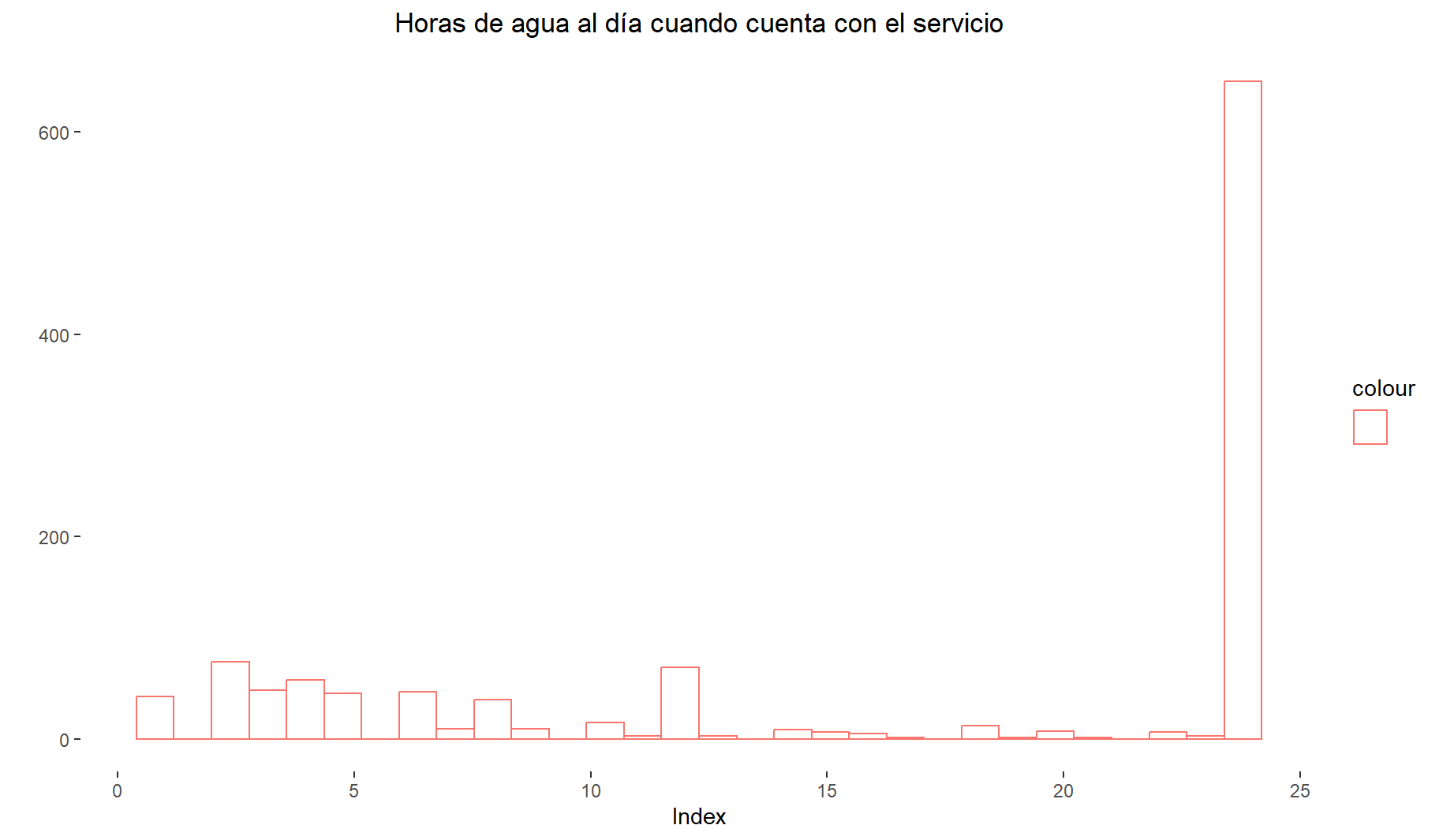
- Asimetría negativa
11.2 Medidas de centralidad
- Variable categórica nominal: np1
library(DescTools)
Mode(datalapop$np1,na.rm = T)[1] No Asistió
attr(,"freq")
[1] 1032
Levels: Asistió No Asistió- Es decir, la mayoría de encuestados no asistió a un cabildo abierto o una sesión municipal durante los últimos 12 meses
============================================================
- Variable categórica ordinal: m1
library(DescTools)
Mode(datalapop$m1,na.rm = T)[1] Regular
attr(,"freq")
[1] 579
Levels: Muy bueno < Bueno < Regular < Malo < Muy maloLa mayoria de gente considera que la labor de Vizcarra es regular
Median(datalapop$m1, na.rm = T)[1] Regular
Levels: Muy bueno < Bueno < Regular < Malo < Muy malo- El 50% de los encuestados considera que la labor de Vizcarra, al menos, fue regular.
============================================================
12 Variable numérica: psc8
library(DescTools)
Mode(datalapop$psc8, na.rm = T)[1] 24
attr(,"freq")
[1] 650- La mayoría de encuestados tiene agua las 24 horas cuando tiene el servicio
Median(datalapop$psc8, na.rm = T)[1] 24- El 50% de encuestados tiene agua, al menos, las 24 horas cuando tienen el servicio
mean(datalapop$psc8, na.rm = T)[1] 16.38363- En promedio, los encuestados tiene agua 16 horas cuando tienen el servicio
describe(datalapop$psc8)datalapop$psc8
n missing distinct Info Mean Gmd .05 .10
1173 0 24 0.829 16.38 9.563 2.0 2.2
.25 .50 .75 .90 .95
6.0 24.0 24.0 24.0 24.0
lowest : 1 2 3 4 5, highest: 20 21 22 23 24Mínimo:
min(datalapop$psc8, na.rm = T) # na.rm = T no considera los valores perdidos[1] 1- El mínimo de horas que un encuestado tiene agua cuando tiene el servicio es una hora.
Máximo:
max(datalapop$psc8, na.rm = T)[1] 24- El máximo de horas que un encuestado tiene agua cuando tiene el servicio es 24 horas.
Rango:
range(datalapop$psc8, na.rm = T)[1] 1 24- El rango de horas que un encuestado tiene agua cuando tiene el servicio esta entre una a 24 horas.
Quantiles:
quantile(datalapop$psc8, na.rm=T) 0% 25% 50% 75% 100%
1 6 24 24 24 - Q1: El 25% de encuestados tiene agua, al menos, 6 horas cuando tienen el servicio
- Q2: El 50% de encuestados tiene agua, al menos, las 24 horas cuando tienen el servicio
- Q3: El 75% de encuestados tiene agua, al menos, las 24 horas cuando tienen el servicio
IQR:
IQR(datalapop$psc8, na.rm = T)[1] 18El 50% intermedio de los datos está entre 6 y 24 horas.
Varianza:
var(datalapop$psc8, na.rm = T) # Varianza[1] 84.17181- desviación
sd(datalapop$psc8, na.rm = T) # Desviación[1] 9.1745213 Medidas de distribución de la variable numérica:
- Asimetría
library(moments)
skewness(datalapop$psc8, na.rm = T)[1] -0.5301169Esto indica que los datos tienen una asimetria negativa, es decir, estos tienden a estar hacia la izquierda.
Curtosis
kurtosis(datalapop$psc8, na.rm = T) #curtosis[1] 1.490921- Esto indica que la distribución es mayor que cero, por tanto, es leptocúrtica.