#getwd()
#setwd("")3 Intervalo de Confianza
Docente: Marylia Cruz
- Descargar las bases de datos
- Cambiar de directorio de trabajo
- Abrir la base de datos
- Comandos básicos
- Intervalo de confianza para una proporción
- Construcción de indicadores
- Intervalo de confianza para una media
3.1 DESARROLLO
Descargar las bases de datos y los paquetes a utilizar
Cambiar de directorio de trabajo
La ruta de trabajo o directorio va a depender de cada computadora. Una opción fácil de saberla es ir al menu - session-set working directory -choose directory
Abrir la base de datos
Importa la base de datos a R. Recuerda que si termina en .dta proviene de stata, si termina con .sav proviene de spss.
library(rio)
datalapop = import("./data/s2/LAPOP_PERU_2019.dta")
#names(datalapop) # solicitar los nombres de las variables
#str(datalapop) # solicitar la estructura de las variables
#class(datalapop) - Carga las siguiebtes Librerias
library(rio) # abrir base de datos
library(psych)
library(ggplot2)# para el gráfico estático
library(gplots) # para solicitar las graficas de error
library(Rmisc)4 Intervalo de confianza para una proporción:
5 V. C. Nominal jc15a = Justificación del cierre del congreso
#str(datalapop$jc15a)datalapop$jc15a = as.factor(datalapop$jc15a)
datalapop$jc15a = factor(datalapop$jc15a,
levels = levels(datalapop$jc15a),
labels = c("Si","No"),
ordered = F)
#str(datalapop$jc15a)#tabla para variable nominal
table(datalapop$jc15a)
Si No
449 313 prop.table(table(datalapop$jc15a)) * 100
Si No
58.92388 41.07612 5.1 Intervalo de confianza para una proporción (en este caso los que sí están a favor del Sí)
# Intervalo de proporciones de los que si justifican el cierre del congreso.
n = 442+302 #El total de jc15a
x = 442 #proporcion que me interesa, por ej., del SÍ
prop.test(x, n, p = NULL,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95, correct = TRUE)
1-sample proportions test with continuity correction
data: x out of n, null probability 0.5
X-squared = 25.969, df = 1, p-value = 3.469e-07
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.5577263 0.6294607
sample estimates:
p
0.594086 confianza: nivel de credilidad de ese dato.
–> Fijarnos PARA LA INTERPRETACION: 95 percent confidence interval: 0.5577263 0.6294607
5.2 INTERPRETACION:
H0: El nivel de la muestra no es igual al nivel de la proporcion
El intervalo de confianza de los que sí justifican el cierre del Congreso oscila entre 55% y 62% al 95% de nivel de confianza.
(En cristiano este resultado señala que si se realiza otra encuesta en otro lado del perú, las personas responderán en favor de la cierre del congreso en ese intervalo de confianza en este caso.)
tabla1 = prop.table(table(datalapop$jc15a)) * 100
tabla1r = as.data.frame(tabla1)
tabla1r Var1 Freq
1 Si 58.92388
2 No 41.076125.3 GRAFICO DE BARRAS (BARPLOT)
#grafico1 <- table(datalapop$jc15a)
# También se puede crear una grafica en porcentaje:
grafico1 <- prop.table(table(datalapop$jc15a)) * 100
grafico1 = as.data.frame(grafico1)
colnames(grafico1) = c("Reg","Freq")
library(ggplot2)
bp = ggplot(grafico1, aes(x = reorder(Reg,Freq), y = Freq, fill = Reg)) +
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Entrevistados según si justifica el cierre del congreso",
y = "% entrevistados", x = "Justifica el cierre al congreso",
subtitle = "", caption = "LAPOP, PERU 2019") +
theme(plot.title = element_text(hjust = 1)) +
theme(panel.background = element_rect(fill = "white", colour = "white")) +
geom_text(aes(label = Freq), vjust = 0.5, color ="Black", size = 5)
bp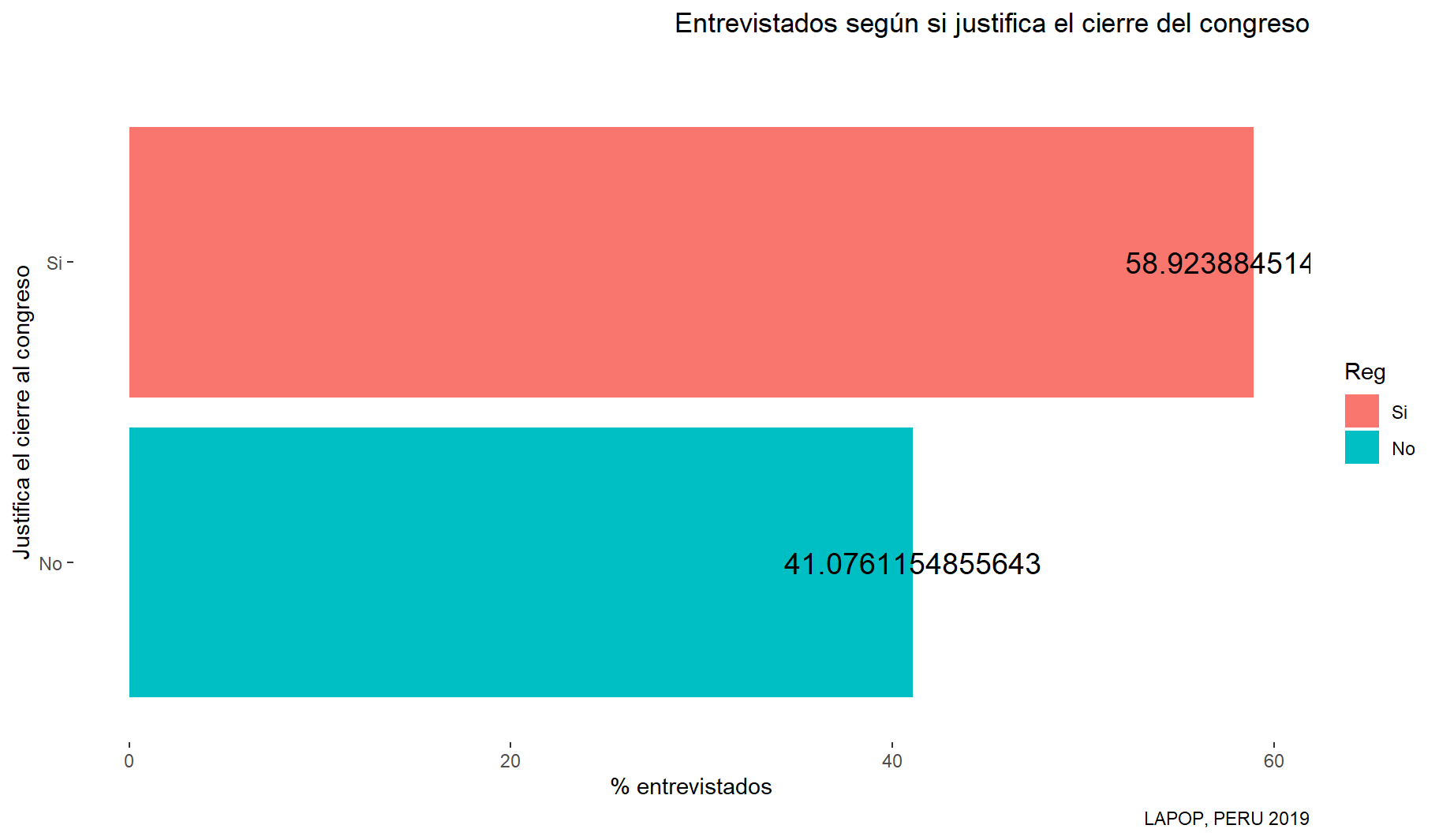
6 Construcción de indicadores
6.1 Creación del indicador APOYO AL SISTEMA POLÍTICO:
Definir qué es un sistema politico.
qué signifca apoyo
Luego las personas que realizan las encuestas, a traves de una serie preguntas van a medir dicho concepto. cómo resumir dichas preguntas en un numero? - Indice aditivo: sumar las variables.
Definimos las variables que conforman el indicador.
# Forma larga:
# lapop$b1 = as.numeric(lapop$b1)
# lapop$b2 = as.numeric(lapop$b2)
# lapop$b3 = as.numeric(lapop$b3)
# lapop$b4 = as.numeric(lapop$b4)
# lapop$b6 = as.numeric(lapop$b6)- A númerica:
# forma corta de convertir varias variables:
datalapop[,c(48:52)] = lapply(datalapop[,c(48:52)],as.numeric)
# del b1 al b6 # numero de la columnas 48 al 526.2 Resumen de las variables:
summary(datalapop$b1) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 2.000 3.000 2.927 4.000 7.000 11 summary(datalapop$b2) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 2.000 4.000 3.824 5.000 7.000 18 summary(datalapop$b3) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.00 2.00 3.00 3.12 4.00 7.00 11 summary(datalapop$b4) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 2.000 3.000 3.463 5.000 7.000 16 summary(datalapop$b6) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 3.000 4.000 4.216 6.000 7.000 23 Sumo las variables: #variable de escala Likert:
- O sea, una persona puede puede como minimo 5 puntos y como maximo 35 puntos.
datalapop$SumaApoyoSistemaPolitico = datalapop$b1 + datalapop$b2 + datalapop$b3 + datalapop$b4 + datalapop$b6
#datalapop$SumaApoyoSistemaPolitico
summary(datalapop$SumaApoyoSistemaPolitico) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
5.00 13.00 18.00 17.56 22.00 35.00 45 Pero mejor lo convertimos a indice adecuado:
- Contrucción de índice de 0 a 100:
datalapop$IndiceASP = ((datalapop$SumaApoyoSistemaPolitico - 5) / 30) * 100
# Restamos el mínimo (5) y divimos entre el mázimo ya restado (30)
# (sería 35, pero ya se restó 5) y finalmente se
# multiplica * 100 (Indice aditivo de 0 a 100)
#Resumen del indicador:
summary(datalapop$IndiceASP) # El comando brinda el resumen de la variable Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 26.67 43.33 41.85 56.67 100.00 45 head(datalapop$IndiceASP)[1] 50.00000 50.00000 43.33333 46.66667 40.00000 NAentonces, si se desea construir un indice de 0 a 100 solo sería * 10:
datalapop$IndiceASP10 = ((datalapop$SumaApoyoSistemaPolitico - 5) / 30) * 10
summary(datalapop$IndiceASP10) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.000 2.667 4.333 4.185 5.667 10.000 45 head(datalapop$IndiceASP10)[1] 5.000000 5.000000 4.333333 4.666667 4.000000 NA- Estadísticos descriptivos del indicador de 0 a 100 (Ya se convirtió en una variable númerica). Entonces, solicitar los indicado para dicha variable:
mean(datalapop$IndiceASP, na.rm = T)[1] 41.85185sd(datalapop$IndiceASP, na.rm = T)[1] 20.623146.3 HISTOGRAMA (HIST)
ggplot(datalapop, aes(x = IndiceASP, color = "")) +
geom_histogram(breaks = seq(105), fill = "white",alpha = 0.5,
position = "identity") +
labs(title = "Apoyo al sistema politico", y = "", x = "Index",
subtitle = "", caption = "ENDO 2020") +
theme(plot.title = element_text(hjust = 0.5)) +
theme(panel.background = element_rect(fill = "white", colour = "white"))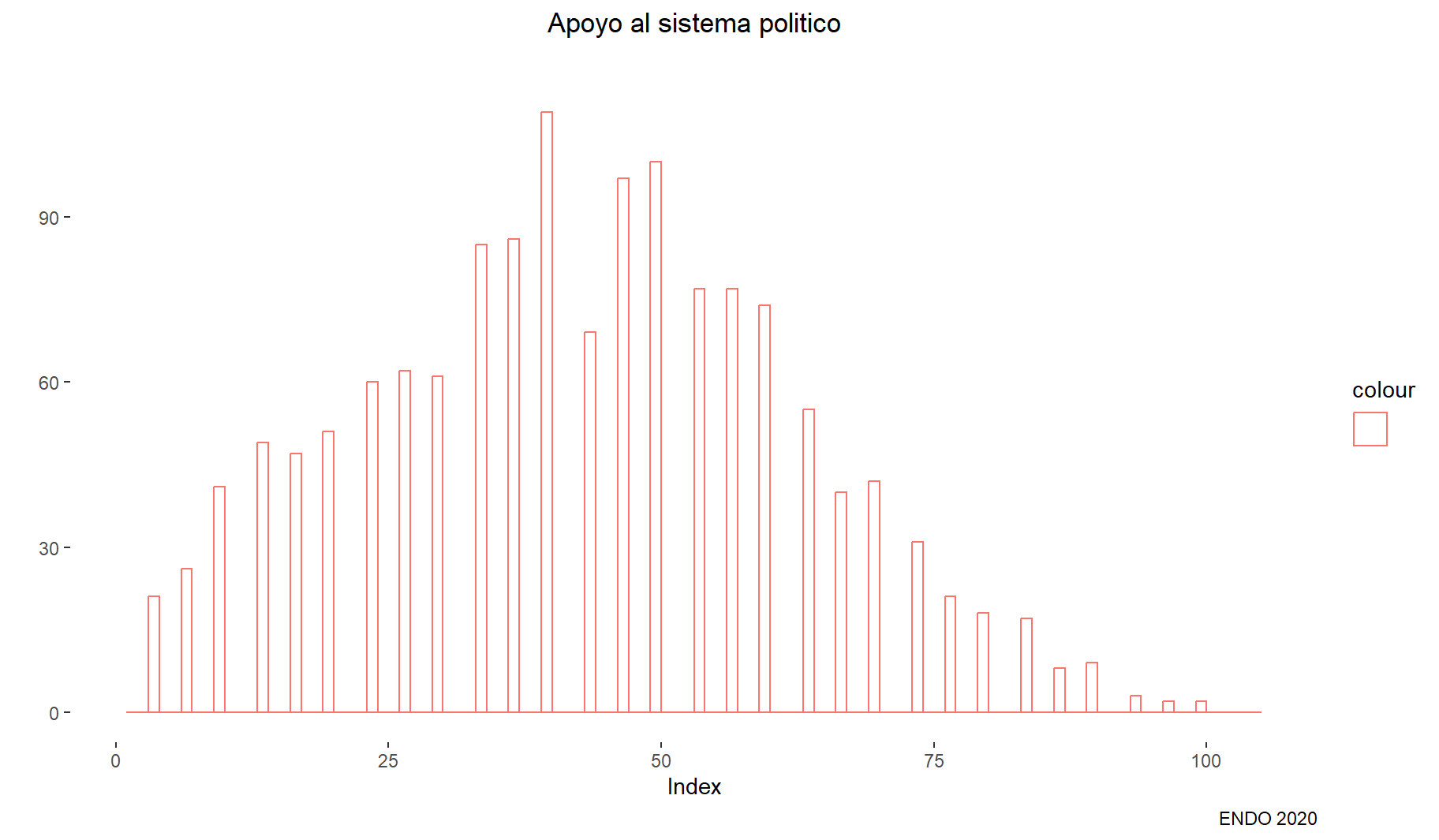
7 INTERVALO DE CONFIANZA PARA UNA MEDIA
- Recuerde que el intervalo de confianza se compone de un limite superior y uno inferior.
###FORMA LARGA
n <- length(datalapop$IndiceASP) # El tamaño válido de la muestra
media <- mean(datalapop$IndiceASP,na.rm = T) # la media
desv <- sd(datalapop$IndiceASP, na.rm = T) # La desviacián estándar
nivelconfianza = 0.95
error.est <- desv / sqrt(n) # Calculamos el error estándar
margen.error <- 1.96 * error.est # nivel de confianza de 90%
lim.inf <- media - margen.error # Límite inferior del intervalo
lim.inf # 39.839[1] 40.81541lim.sup <- media + margen.error # Límite superior del intervalo
lim.sup # 42.80437[1] 42.8883- A un nivel de confianza del 95% el promedio del apoyo al sistema politico de los peruanos oscila entre 39.839 y 42.80437
# FORMA CORTA:
library(Rmisc)
datalapop <- datalapop[!is.na(datalapop$IndiceASP), ] # eliminar valores perdidos
ci.indicador <- CI(datalapop$IndiceASP, ci = 0.95) # calcula el nivel de confianza
ci.indicador upper mean lower
42.90482 41.85185 40.79888 Varía la interpretacion pues se han eliminado los casos perdidos:
INTERPRETACION:
- A un nivel de confianza del 95% el promedio del apoyo al sistema politico de los peruanos oscila entre 40.79888 y 42.90
7.1 BARRAS DE ERROR:
plotmeans(datalapop$IndiceASP ~ datalapop$q1,
p = 0.95,
xlab = "Sexo",
ylab = "Apoyo al sistema",
main = "Mean Plot \n with 95% CI")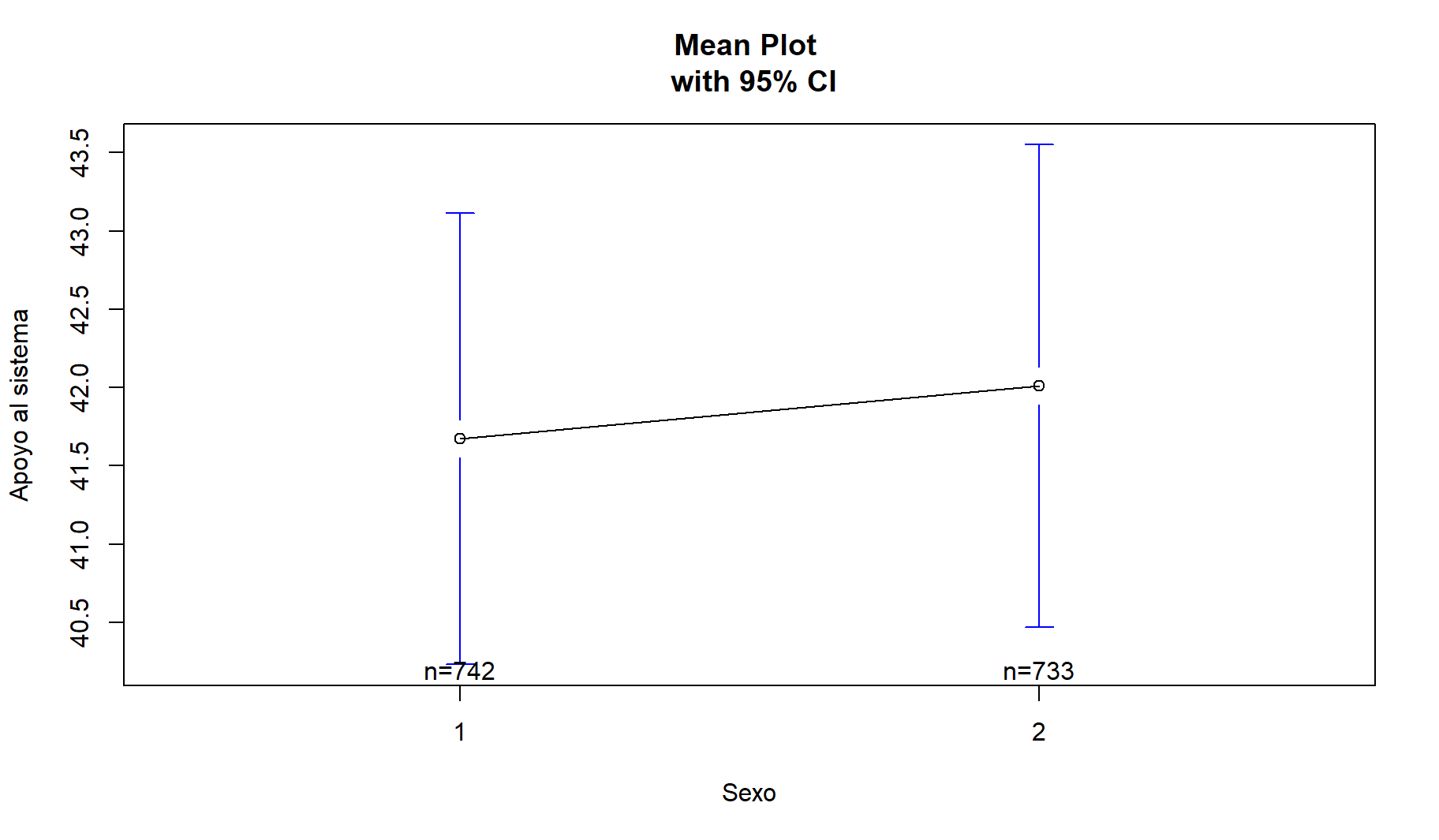
parace que no hay mucha diferencia entre el sexo al apoyo del sistema pues el posible rango de valores de muejeres casi son los mismos que de hombres
la bolita indica el promedio
los bigotes indican los niveles de confianza de los promedios de cada grupo
7.2 GRAFICO DE CAJAS (BOXPLOT)
datalapop <- datalapop[!is.na(datalapop$jc15a), ] # Eliminando casos perdidoslibrary(ggplot2)
library(plotly)
p1 <- ggplot(datalapop, aes(x = jc15a, y = IndiceASP, color =jc15a)) +
geom_boxplot() + coord_flip() +
theme(legend.position = "top", axis.text.y = element_blank(),
panel.background=element_rect(fill = "white", colour = "white")) +
geom_jitter(shape = 16, position = position_jitter(0.2)) +
labs(title = "El apoyo al sistema político según el sexo", x = "",
y ="Index", subtitle = "", caption = "ENDO 2020") +
scale_y_continuous(breaks = (1:100))
ggplotly(p1)Figure 1: El apoyo al sistema político según el sexo (ENDO 2020).
Interpretación: